I have wanted to spend some more time recently playing with Replicated LevelDB in ActiveMQ. Not wanting to hit a cloud environment such as EC2, I set up 3 VirtualBox nodes on my workstation running Fedora. The host system needs to be fairly beefy – you need at least a dedicated CPU core per image + RAM. The setup itself was relatively straightforward except for a couple of gotchas. I didn’t use Docker or similar simply because I haven’t played with it; as a rule I try not to introduce too many new pieces into a setup, otherwise it runs into a yak shaving exercise. What follows is an outline of how I got it running, and some of the things I bumped my head against.
My approach was to get the software set up on a single disk image, and then replicate that over to another couple of VMs, tweaking to get the clustering working correctly. Turns out, that works pretty well. When creating VirtualBox images, set the Network Adapter1 as a Bridged Adapter to your ethernet port, with Promiscuous Mode set to “Allow All” .
As a starting point, I downloaded Zookeeper 3.4.6 and ActiveMQ 5.10, and unzipped them into /opt, and created symlinks as /opt/zk and /opt/activemq respectively.
If you follow the setup instructions from the ActiveMQ site, the first thing you’ll see that what’s not covered is the Zookeeper (ZK) setup. Thankfully, the ZK website itself has a good breakdown of how to do this in the Clustered (Multi-Server) Setup section of the Administrator’s guide. The standard config file I used was /opt/zk/conf/zk.conf, configured with the following:
tickTime=2000 dataDir=/var/zk/data clientPort=2181 initLimit=5 syncLimit=2
You have to create the /var/zk/data directory yourself. This is where ZK keeps its logs, as well as a file called myid, which contains a number that defines which node in the cluster this particular machine is.
Later, once you know the IP addresses of the machines you add the following to the end of the zk.conf file (here I’m using a 3 node cluster):
server.1=192.168.0.8:2888:3888 server.2=192.168.0.13:2888:3888 server.3=192.168.0.12:2888:3888
The number that follows server. corresponds to the contents of the myid file on that particular server.
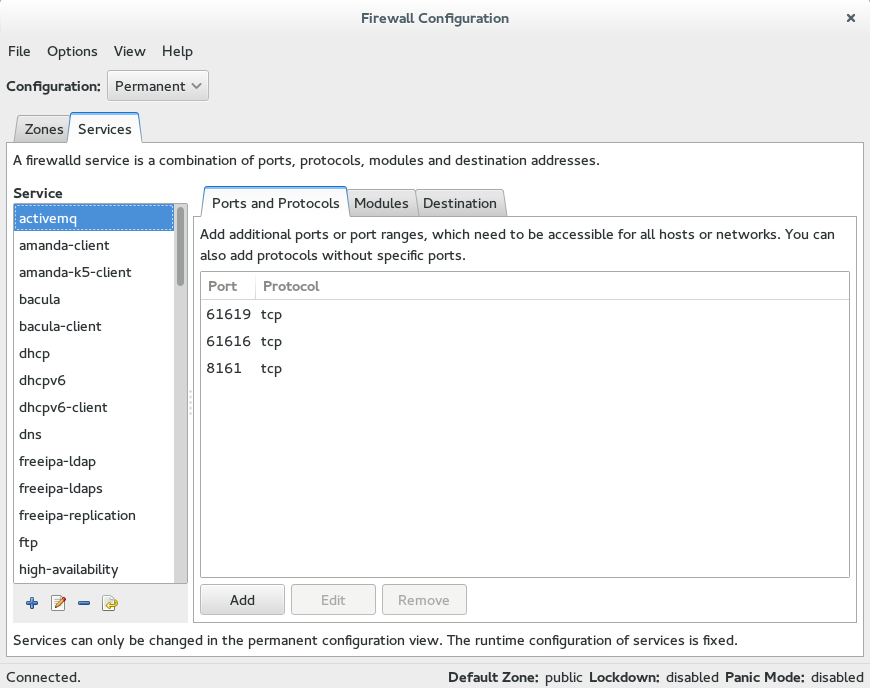
For Zookeeper to work correctly, 3 ports have to be opened on the server’s firewall:
- 2181 – the port that clients will use to connect to the ZK ensemble
- 2888 – port used by ZK for quorum election
- 3888 – port used by ZK for leader election
The firewall changes that you’ll need for ActiveMQ are:
- 61616 – default Openwire port
- 8161 – Jetty port for web console
- 61619 – LevelDB peer-to-peer replication port
On Fedora, you access the firewall through the Firewall program (oddly enough). I set up ZK and ActiveMQ as Services in the Permanent configuration (not Runtime), and turned those two services on in the Public zone (default used).
The ActiveMQ configuration changes are pretty straightforward. This is the minumum config change that was needed in the conf/activemq.xml:
<persistenceAdapter>
<replicatedLevelDB zkAddress="192.168.0.8:2181,192.168.0.13:2181,192.168.0.2181"
directory="${activemq.data}/LevelDB"
hostname="192.168.0.8"/>
</persistenceAdapter>
The zkAddress is pretty clear – these are the ZK nodes and client ports of the ZK ensemble. The data directory is defined by directory. I’ll get onto the hostname attribute in a little while.
Once I had everything set up, it was time to start playing with the cluster. Starting the first ActiveMQ node was problem free – it connected to ZK, and waited patiently until one other ActiveMQ node connected to it (quorum-based replication requires numNodesInCluster/2 + 1 instances). When a second ActiveMQ node was started, the master exploded:
INFO | Using the pure java LevelDB implementation. INFO | No IOExceptionHandler registered, ignoring IO exception java.io.IOException: com.google.common.base.Objects.firstNonNull(Ljava/lang/Object;Ljava/lang/Object;)Ljava/lang/Object; at org.apache.activemq.util.IOExceptionSupport.create(IOExceptionSupport.java:39)[activemq-client-5.10.0.jar:5.10.0] at org.apache.activemq.leveldb.LevelDBClient.might_fail(LevelDBClient.scala:552)[activemq-leveldb-store-5.10.0.jar:5.10.0] at org.apache.activemq.leveldb.LevelDBClient.replay_init(LevelDBClient.scala:657)[activemq-leveldb-store-5.10.0.jar:5.10.0] at org.apache.activemq.leveldb.LevelDBClient.start(LevelDBClient.scala:558)[activemq-leveldb-store-5.10.0.jar:5.10.0] at org.apache.activemq.leveldb.DBManager.start(DBManager.scala:648)[activemq-leveldb-store-5.10.0.jar:5.10.0] at org.apache.activemq.leveldb.LevelDBStore.doStart(LevelDBStore.scala:235)[activemq-leveldb-store-5.10.0.jar:5.10.0] at org.apache.activemq.leveldb.replicated.MasterLevelDBStore.doStart(MasterLevelDBStore.scala:110)[activemq-leveldb-store-5.10.0.jar:5.10.0] at org.apache.activemq.util.ServiceSupport.start(ServiceSupport.java:55)[activemq-client-5.10.0.jar:5.10.0] at org.apache.activemq.leveldb.replicated.ElectingLevelDBStore$$anonfun$start_master$1.apply$mcV$sp(ElectingLevelDBStore.scala:226)[activemq-leveldb-store-5.10.0.jar:5.10.0] at org.fusesource.hawtdispatch.package$$anon$4.run(hawtdispatch.scala:330)[hawtdispatch-scala-2.11-1.21.jar:1.21] at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1145)[:1.7.0_60] at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:615)[:1.7.0_60] at java.lang.Thread.run(Thread.java:745)[:1.7.0_60] INFO | Stopped LevelDB[/opt/activemq/data/LevelDB]
After a bit of scratching, I happened upon AMQ-5225 in the ActiveMQ JIRA. It seems that the problem is with a classpath conflict in 5.10 (readers from the future – if you’re using a newer version, you won’t see this problem 🙂 ). To get around it, follow these instructions:
1. remove pax-url-aether-1.5.2.jar from lib directory 2. comment out the log query section <bean id="logQuery" class="org.fusesource.insight.log.log4j.Log4jLogQuery" lazy-init="false" scope="singleton" init-method="start" destroy-method="stop"> </bean>
When I made the changes, everything started to work without this exception. Once the second ActiveMQ instance was started, the master sprung to life and started logging the following to the console:
WARN | Store update waiting on 1 replica(s) to catch up to log position 0. WARN | Store update waiting on 1 replica(s) to catch up to log position 0. WARN | Store update waiting on 1 replica(s) to catch up to log position 0. ...
The slave on the other hand had the following text output:
INFO | Using the pure java LevelDB implementation. INFO | Attaching to master: tcp://localhost.localdomain:61619 WARN | Unexpected session error: java.net.ConnectException: Connection refused INFO | Using the pure java LevelDB implementation. INFO | Attaching to master: tcp://localhost.localdomain:61619 WARN | Unexpected session error: java.net.ConnectException: Connection refused ...
Ad infinitum.
After a bunch of fruitless searching, I realised that the answer was right in front of me in the slave output:
(Attaching to master: tcp://localhost.localdomain:61619). It seems that the master was registering itself into ZK with its hostname (localhost.localdomain).
Once that clicked, the documentation led me to the hostname attribute on the replicatedLevelDB tag in the persistenceAdapter. This value is used by the broker to advertise its location through ZK so that slaves can connect to its LevelDB replication port. The default behaviour sees ActiveMQ trying to automatically work out the hostname.
That value being used was coming from /etc/hosts – here’s the default contents for that file:
127.0.0.1 localhost.localdomain localhost ::1 localhost6.localdomain6 localhost6
I would imagine that in a proper network setup this wouldn’t typically happen, as the box name would be worked out through DHCP + internal DNS. Simply overriding the default behaviour of the zkAddress by putting in the IP address of the virtual machine worked a treat.
With a test client on the host machine running the 3 VirtualBox instances I was able to connect to all 3 nodes and fail them over without problems.
ZK uses a list to work out which ActiveMQ slave node is going to take control when the master broker dies; the ordering is defined by who connected to the ensemble first. If you have less than quorum of ActiveMQ nodes running, no ActiveMQ nodes in the cluster will accept connections (this is managed by the replicated LevelDB store).
Since ZK also maintains a quorum, when less than the required number of servers are available, the remaining nodes will shut down their client port (2181). This will disconnect all the brokers from the ensemble, and the master broker to shut down its transportConnectors.
Happy replicated LevelDB-ing!